Leveraging Kubernetes For Microservices Based Cloud Strategy
Enterprise applications have to be designed upfront for scalability and change. This has significant implications for both application architecture and application infrastructure. Application architecture is evolving from unmanageable monolithic or three-tier patterns to interconnected microservices. Microservices introduce new form factors not only for functionality and team-size (the so-called two-pizza teams), but also for the unit of infrastructure. It is not surprising that a portable container or a pod of handful interrelated containers often works out as the most befitting unit of infrastructure for microservices-based architecture. Fortunately, container-based scalable infrastructure is a reality today, thanks to the Kubernetes project incepted in and open-sourced by Google in 2014. But for the sake of business agility, it is critical for enterprise development teams to focus on the business logic with the insurance that deployment onto a suitable infrastructure would be relatively painless.
How LunchBadger integrates with Kubernetes
This is where LunchBadger comes in. LunchBadger offers a visual interface called the Canvas to model and define services, and deploy them onto a Kubernetes-based infrastructure in a single pane of glass. These services could be business-to-business services or intra-organization, or even intra-application microservices. They could be synchronously invoked REST URLs or asynchronously invoked serverless functions. In any case, it allows the developer to focus on application development and deploy the application onto a scalable Kubernetes-based infrastructure without any administrative intervention. LunchBadger is a Kubernetes-native solution such that the application developer does not switch from the Canvas, even as the requisite container instances are created and orchestrated behind the scene. So, let’s take a tour of life without LunchBadger – how it takes a sequence of steps to deploy and expose a service on a Kubernetes cluster – and then explore how LunchBadger cuts down the complexity to a one-click deployment.
Kubernetes In A Nutshell
Kubernetes is an deployment and orchestration framework for containerized applications. Given a farm of compute resources, Kubernetes allocates resources to containers and performs replication, scaling, failover, and other management tasks necessary to run enterprise applications reliably with efficient resource utilization.
Datacenters that run applications on virtualization technologies like VMWare depend on a suite of tools like VSphere to deploy and manage Virtual Machines on a server farm. Kubernetes plays a similar role in the world of containerized applications.
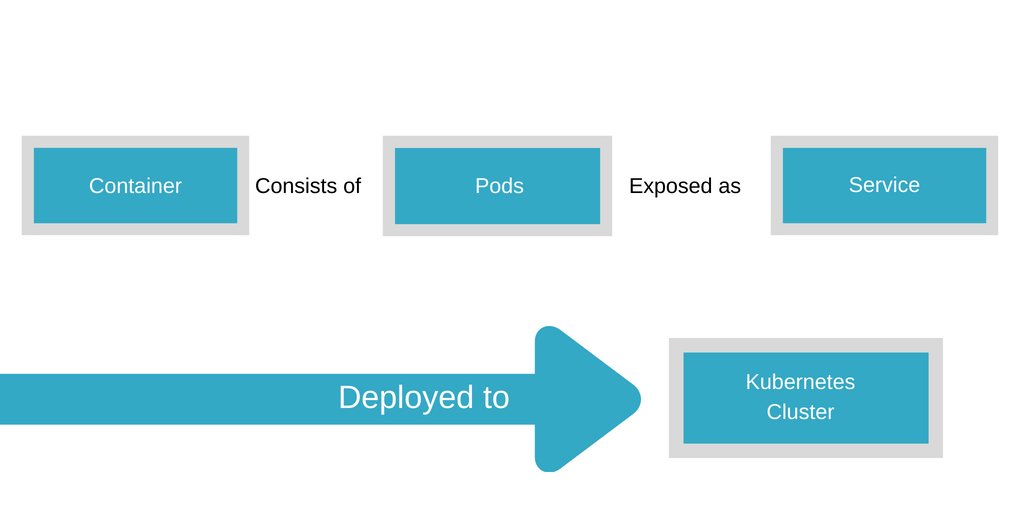
The unit of deployment in Kubernetes is a ‘pod’. A Pod consists of one a small number of containers that are deployed and scaled together as a unit. A cluster consists of Nodes, which are compute resources that can join or leave a cluster. Pods can be deployed onto a running cluster using a deployment specification. Among other attributes, a deployment spec includes the desired state of the cluster in terms of number of replicas of a pod that should be running at any point in time. The run-time ensures that the desired number of replicas are always maintained, even if one or more pods crash. Secondly, a deployment spec can be used to run rolling upgrades on the specified pods.
Finally, Kubernetes defines ‘Service‘ as a location-independent abstraction of the server processes running within pods. That is, while the pods may be allocated to different compute resources at different times based on availability, the service endpoint remains unchanged, so that it can be discovered and accessed externally without any disruption.
Kubernetes also comes with a command-line tool called kubectl for deploying containerized applications and managing services.
Let’s break it down:
How Kubernetes, Microservices And Serverless work together
Martin Fowler lists out a few characteristics of Microservices architecture, two of which may be worth calling out here:
- Componentization via Services
- Smart Endpoints and “dumb pipes”
Kubernetes is uniquely positioned to be the deployment platform of choice for Microservices. The ‘components’ of a microservices-based application can be developed, built, tested, deployed and scaled independently. Kubernetes uses containers, and containers enable application components to be portable and easily integrated in a larger application.
In event-driven scenarios, traditionally, enterprise service bus or similar technologies have been used to process message streams and trigger workflows. In microservices, the preference is to reduce complexity of the pipeline between application components, because otherwise the pipeline itself tends to become a monolithic component that has to be deployed and managed separately. Event driven microservices can be deployed as serverless functions.
With Kubernetes-native serverless frameworks like kubeless, Kubernetes is capable of serving as the deployment infrastructure for event-driven microservices as well.
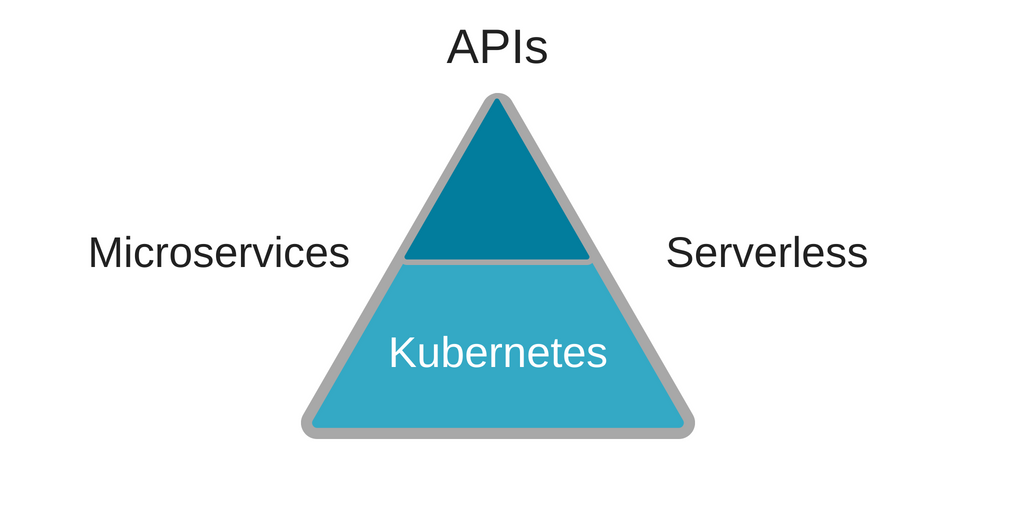
Microservices components – event-driven or otherwise, have to expose an interface for other components or the external world to access its services. This is where APIs have to be carefully defined, and an infrastructure for setting up and managing secure API endpoints has to be supported. LunchBadger brings together a development platform for microservices – both synchronous and event-driven (serverless) – with an API management framework, with end-to-end development and deployment support.
Over the next few posts, we’ll cover tactical examples, guides and walk through how-tos so you can deploy a service in Kubernetes, understand and create a Kubernetes deployment spec, understand and create a Kubernetes Service Spec or just what Kubernetes is all about.